Appearance
激活函数
1. 激活函数的作用
2. 激活函数的特征
3. 常用的激活函数
3.1 Sigmoid函数(逻辑函数)
公式如下:
图形如下: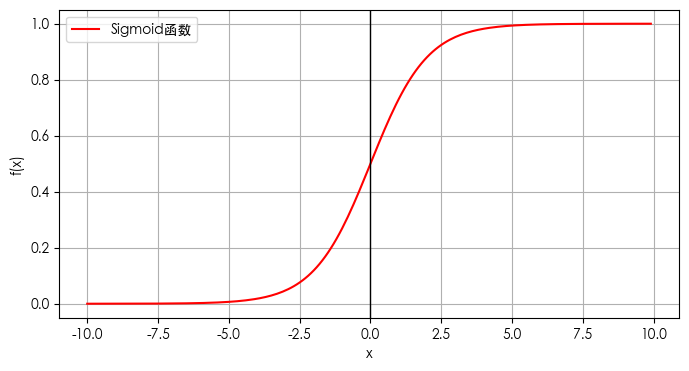
输出范围:
Sigmoid函数的输出界限在0和1之间,包含两端。这意味着它可以将任意实数映射到一个范围在0到1之间的值。
形状:
Sigmoid函数的图像是一个S形曲线,因此得名。它在
输出解释:
接近1的值表示高度激活,而接近0的值表示低激活。这可以直观地理解为神经元被激活的概率。
在神经网络中的应用:
- 二分类问题:Sigmoid函数最典型的应用场景是二分类问题,其中模型需要将输入数据分为两个类别。在神经网络中,Sigmoid函数可以作为输出层的激活函数,将网络的输出映射到(0, 1)的概率范围内,表示样本属于某个类别的概率。
- 逻辑回归:逻辑回归是一种常用的统计学习方法,用于建立分类模型。在逻辑回归中,Sigmoid函数被用作逻辑函数(Logistic function),用于将线性模型的输出转换为概率值。
- 隐藏层:虽然现在Sigmoid函数的使用已经被更先进的激活函数所取代,但Sigmoid函数仍然在某些特定的应用场景中具有一定的用途,例如在神经网络的隐藏层中,Sigmoid函数可以增加网络的非线性特性,有助于提高网络的学习能力。
优点:
- 平滑、易于求导,这使得它在深度学习中得到了一定的应用。
- Sigmoid函数的导数可以用自身表示,这在计算梯度下降时非常方便。
缺点:
- 激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
- 当输入值非常大或非常小的时候,Sigmoid函数的梯度接近于0,这会导致在训练神经网络时梯度消失问题的出现。
3.2 Tanh(双曲正切函数)
公式如下:
图形如下: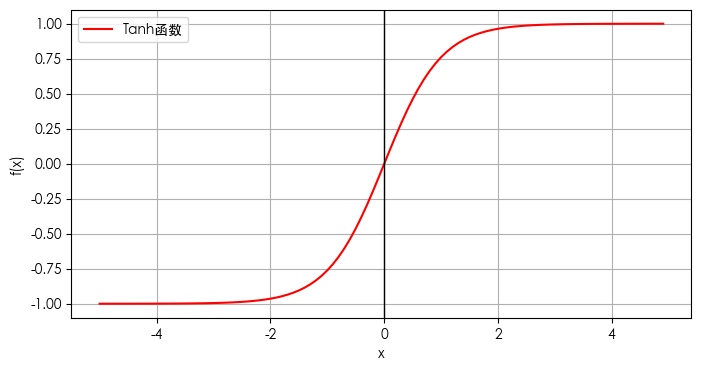
输出范围:
Tanh函数的输出范围在-1和1之间,这使得它在处理需要输出范围在这个区间内的问题时非常有用。
形状:
Tanh函数的图像是一个S形曲线,与Sigmoid函数类似,但它是关于原点对称的。
输出解释:
接近1的值表示高度激活,接近-1的值表示低激活。这可以直观地理解为神经元被激活的强度。
在神经网络中的应用:
- 隐藏层:Tanh函数常用于神经网络的隐藏层,因为它的输出均值为0,这有助于缓解梯度下降过程中的梯度消失问题,特别是在深层网络中。
- 输出层:Tanh函数较少用于输出层,除非输出范围为(-1, 1)的任务。
优点:
- Tanh函数的输出均值为0,这有助于提高模型的收敛速度。 = Tanh函数的导数可以用自身表示,这在计算梯度下降时非常方便。
缺点:
- 当输入值非常大或非常小的时候,Tanh函数的梯度接近于0,这会导致在训练神经网络时梯度消失问题的出现。
- Tanh函数的计算量比Sigmoid函数大,因为它的表达式中包含两个指数函数。
3.3 ReLU(线性整流函数)
公式如下:
图形如下: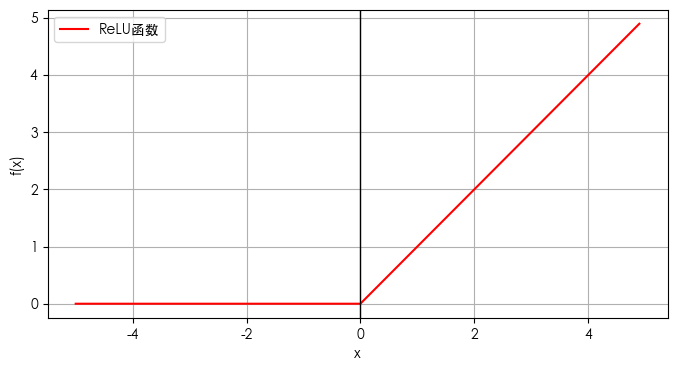
输出范围:
ReLU函数的输出范围在0到正无穷大,即所有负值都被置为0,而正值保持不变。
形状:
ReLU函数的图像是一条斜率为1的直线,从原点开始,对于所有负输入值,函数值为0。
输出解释:
ReLU函数的输出可以被解释为对输入值的非负部分的线性响应,而负值部分则被抑制。
在神经网络中的应用:
- 隐藏层:ReLU函数因其计算简单和缓解梯度消失问题的特性,常被用于神经网络的隐藏层。
- 卷积神经网络(CNN):在图像处理任务中,ReLU函数被广泛用作激活函数,以提取图像特征。
- 循环神经网络(RNN)和长短时记忆网络(LSTM):ReLU函数也用于这些网络结构中,以解决梯度消失问题。
优点:
- 非饱和性:ReLU在正区间
上是线性的,没有梯度消失问题,因此在反向传播过程中能够更有效地传播梯度。 - 稀疏激活性:由于ReLU在负值部分输出为0,因此它引入了稀疏性,使得神经网络中的许多神经元变得不活跃,有助于减少过拟合并提高模型的泛化能力。
- 计算简单:ReLU的计算简单且高效,只需比较输入是否大于零即可,不涉及复杂的数学运算,因此在实际应用中的计算开销较小。
缺点:
- 神经元死亡问题:当输入为负值时,ReLU的梯度为0,这可能导致某些神经元在训练过程中始终保持静默,不再更新其权重,这种现象被称为“神经元死亡”。
3.4 leaky ReLU(泄露整流函数)
公式如下:
图形如下: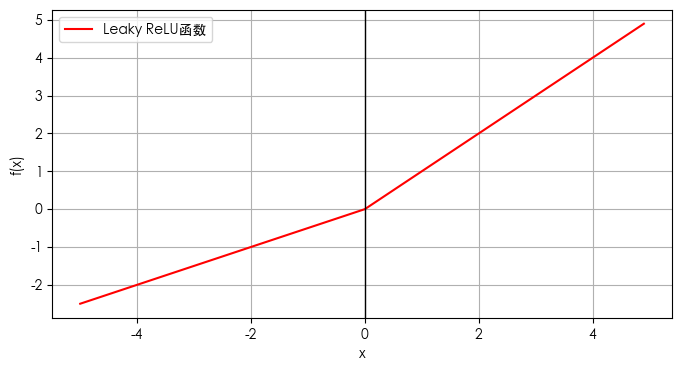
输出范围:
Leaky ReLU函数的输出范围是整个实数集,因为它允许负值输入时有非零输出,这与标准ReLU函数不同。
形状:
Leaky ReLU函数的图像是一个分段线性函数,对于正输入值,函数值为
输出解释:
Leaky ReLU函数的输出可以被解释为对输入值的非线性响应,其中负值部分通过一个小的斜率
在神经网络中的应用:
- 隐藏层:Leaky ReLU函数常用于神经网络的隐藏层,以解决标准ReLU函数中的“死亡ReLU”问题,即某些神经元可能永远不会被激活(即输入始终为负值),导致这些神经元在整个训练过程中都没有贡献。
- 梯度流动:通过在负区间引入一个小的斜率
,Leaky ReLU确保了所有神经元都有梯度,从而避免了梯度消失问题。
优点:
- 非线性:与ReLU一样,Leaky ReLU引入了非线性特性,使得神经网络能够学习复杂的模式。
- 稀疏激活:尽管Leaky ReLU在负区间不会完全变为零,但它仍然保留了一定的稀疏性,有助于提高模型的效率和性能。
- 避免Dying ReLU问题:通过在负区间引入一个小的斜率
,Leaky ReLU确保了所有神经元都有梯度,从而避免了Dying ReLU问题。
缺点:
- 参数选择:对于
的值比较敏感,需要调参以获得最佳性能。
3.5 Softmax(软最大函数)
公式如下:
图形如下:
输出范围:
Softmax函数的输出值范围在0到1之间,并且所有输出值的总和为1,形成一个概率分布。
形状:
Softmax函数的图像是多维空间中的一个曲面,它将输入向量的每个元素映射到一个概率值。
输出解释:
Softmax函数的输出可以被解释为模型对于每个类别的预测概率,使得输出值具有概率意义,可以直接用于概率解释和决策。
在神经网络中的应用:
- 多分类问题:Softmax函数常用于神经网络的输出层,特别是在处理多分类问题时,它可以将神经网络的输出转换为一个概率分布,表示样本属于每个类别的概率。
- 交叉熵损失:在多分类问题中,Softmax函数通常与交叉熵损失函数(Cross-Entropy Loss)结合使用,以优化模型参数。
优点:
- 概率解释:Softmax函数的输出可以直接解释为概率,这使得模型的输出具有直观的统计意义。
- 归一化:Softmax函数将输出归一化为概率分布,使得不同类别的输出值可以直接比较。
- 多类别兼容:Softmax函数适用于两个以上的多类别分类问题。
缺点:
- 数值稳定性问题:当输入值非常大或非常小的时候,Softmax函数可能会遇到数值稳定性问题,如溢出或下溢。为了解决这个问题,通常从指数函数中减去最大值再计算。